Vorlesungsskript 26
Bäume
Im Seminar Mathematische Grundlagen der Computerlinguistik haben Sie bereits Bäume kennengelernt. Bäume spielen in der (Computer)linguistik eine wichtige Rolle, u.a. deshalb, weil sie genutzt werden, um die syntaktische Struktur von Sätzen zu beschreiben. Sie haben Bäume als mathematische Objekte kennengelernt. In dieser Vorlesung wollen wir uns einige Möglichkeiten angucken, Bäume als Python-Datenstrukturen zu repräsentieren. So können wir dann Programme schreiben, die Bäume verarbeiten, z.B. Parser, die die syntaktische Struktur von Sätzen erkennen. Bei dieser Gelegenheit lernen wir, wie wir in Python unsere eigenen Datentypen definieren können.
Verschiedene Arten von Syntaxbäumen
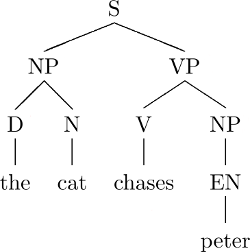
Man unterscheidet zwischen Konstituentenbäumen und Dependenzbäumen. In Konstituentenbäumen entsprechen Blätter Wörtern und interne Knoten (d.h. Nicht-Blätter) entsprechen Konstituenten mit zwei oder mehr Wörtern. Direkte Dominanz zwischen zwei Knoten A und B bedeutet, dass B Teil der Konstituente ist, der A entspricht. Zum Beispiel:
In Dependenzbäumen gibt es dagegen keine Konstituenten. Alle Knoten entsprechen Wörtern. Direkte Dominanz zwischen zwei Knoten A und B bedeutet, dass das Wort B vom Wort A direkt abhängig ist. Man nennt B den Dependenten und A seinen Kopf. Oft haben die Kanten eines Dependenzbaums Etiketten, die angeben, was die genaue grammatische Relation zwischen Kopf und Dependent ist. Zum Beispiel:
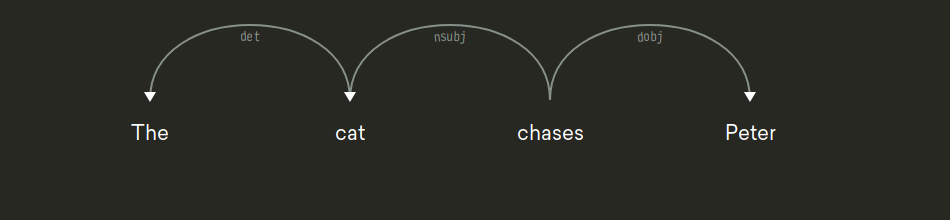
Hier ist das Verb chases die Wurzel. Von ihm hängen zwei Wörter
direkt ab: cat (das Subjekt, die grammatische Relation ist
nsubj) und Peter (das direkte Objekt, die grammatische
Relation ist dobj). Von cat ist wiederum ein Wort abhängig,
nämlich The (das ist sein Determinierer, die grammatische Relation ist
det).
Unterbäume
Als direkten Unterbaum (engl. immediate subtree) eines Baums T bezeichnen wir einen Baum U, dessen Wurzel rU eins der Kinder der Wurzel von T ist und der ansonsten aus allen Knoten besteht, die von rU dominiert werden, und aus den Kanten zwischen ihnen. Der oben abgebildete Konstituentenbaum hat zum Beispiel diese beiden direkten Unterbäume:
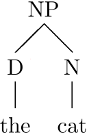
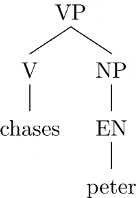
Bäume als Listen repräsentieren
Um Bäume als Python-Objekte zu repräsentieren, können wir z.B. Listen benutzen. Ein Baum wird dabei durch eine Liste dargestellt. Ihr erstes Element ist das Etikett der Wurzel. Jedes weitere Element steht für einen direkten Unterbaum, auf die gleiche Weise als Liste dargestellt. Der oben abgebildete Konstituentenbaum wird so durch die folgende Liste repräsentiert:
ctree = ['S',
['NP',
['D',
['the']],
['N',
['cat']]],
['VP',
['V',
['chases']],
['NP',
['EN',
['peter']]]]]Und der oben abgebildete Dependenzbaum so (wir ignorieren fürs Erste die grammatischen Relationen):
dtree = ['chases',
['cat',
['The']],
['Peter']]Nachdem wir nun eine Python-Repräsentation für Bäume festgelegt haben, können wir Funktionen definieren, die Sachen mit Bäumen machen:
def leaf_labels(tree):
"""Returns an iterable of the labels of all leaves of the given tree.
"""
if len(tree) == 1: # is leaf
yield tree[0] # label
else:
for subtree in tree[1:]:
yield from leaf_labels(subtree)>>> list(leaf_labels(ctree))
['the', 'cat', 'chases', 'peter']
>>> list(leaf_labels(dtree))
['The', 'Peter']def preorder(tree):
"""Does a preorder traversal of the given tree.
Returns an iterable containing the labels of all nodes in preorder, that
is: the label of the root followed by the labels of all immediate subtrees,
in preorder.
"""
yield tree[0] # label
for subtree in tree[1:]: # subtrees
yield from preorder(subtree)
def postorder(tree):
"""Does a postorder traversal of the given tree.
Returns an iterable containing the labels of all nodes in postorder, that
is: the label of the root after the labels of all immediate subtrees,
in postorder.
"""
for subtree in tree[1:]: # subtrees
yield from postorder(subtree)
yield tree[0] # label>>> list(preorder(ctree))
['S', 'NP', 'D', 'the', 'N', 'cat', 'VP', 'V', 'chases', 'NP', 'EN', 'peter']
>>> list(postorder(ctree))
['the', 'D', 'cat', 'N', 'NP', 'chases', 'V', 'peter', 'EN', 'NP', 'VP', 'S']
>>> list(preorder(dtree))
['chases', 'cat', 'The', 'Peter']
>>> list(postorder(dtree))
['The', 'cat', 'Peter', 'chases']Geht es besser?
Bäume als (verschachtelte) Listen darzustellen wie oben funktioniert, aber die Lesbarkeit und Wartbarkeit sowohl dieser Darstellungen als auch der Funktionen, die darauf operieren, lässt noch zu wünschen übrig. Zum einen sieht man den Listen nicht unbedingt an, dass es sich um Baumdarstellungen handelt und nicht um irgendwelche beliebigen Listen. Klarer wäre es, wenn wir z.B. schreiben könnten:
ctree = Tree('S',
Tree('NP',
Tree('D',
Tree('the')),
Tree('N',
Tree('cat'))),
Tree('VP',
Tree('V',
Tree('chases')),
Tree('NP',
Tree('EN',
Tree('peter')))))
dtree = Tree('chases',
Tree('cat',
Tree('the')),
Tree('Peter'))Zum anderen: Um die Funktionen zu verstehen, muss man wissen, dass tree[0] das Etikett ist und tree[1:] die direkten Unterbäume. Dieser
Aspekt unserer Darstellung ist relativ willkürlich; wir hätten z.B. das Etikett
auch ans Ende der Liste setzen können oder zwischen Etikett und Unterbäumen
noch ein Kantenetikett einfügen können (für Dependenzbäume). Wenn wir das
Format unserer Bäume irgendwann einmal ändern, müssen alle diese Funktionen
geändert werden, denn wenn wir versehentlich so eine Funktion auf einen Baum in
einem anderen Format anwenden, kann es großes Chaos geben. Es wäre daher gut,
die Darstellung und die Funktionen irgendwie zu „koppeln“, sodass man sicherer
sein kann, dass die Funktion dem aktuellen Baumformat entspricht.
Es ist daher an der Zeit, uns nicht länger mit der Handvoll Standard-Datentypen (Listen usw.) zu begnügen, die Python zur Verfügung stellt. Es ist Zeit, unseren ersten eigenen Datentyp zu definieren, und zwar einen speziell für Bäume. Das ermöglicht dann eine klarere Darstellung und Kopplung von Darstellung und Funktionen.